
 Reactor 核心
Reactor 核心
# 介绍
Reactor 是一个用于 JVM 的完全非阻塞的响应式编程框架,具备高效的需求管理(即对 “背压(backpressure)” 的控制)能力。它与 Java 8 函数式 API 直接集成,比如 CompletableFuture, Stream, 以及 Duration。它提供了异步序列 API Flux(用于 [N] 个元素)和 Mono(用于 [0|1] 个元素),并完全遵循和实现了 “响应式扩展规范”(Reactive Extensions Specification)。
Reactor 的 reactor-ipc 组件还支持非阻塞的进程间通信(inter-process communication, IPC)。 Reactor IPC 为 HTTP(包括 Websockets)、TCP 和 UDP 提供了支持背压的网络引擎,从而适合 应用于微服务架构。并且完整支持响应式编解码(reactive encoding and decoding)。
# 依赖
<!--时间2025年2月24日14:38:41的最新版本-->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-bom</artifactId>
<version>2024.0.3</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
2
3
4
5
6
7
8
9
10
11
12
<dependencies>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-core</artifactId>
</dependency>
<!--单元测试的相关包,可以不引用-->
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
2
3
4
5
6
7
8
9
10
11
12
# 拓展
如果想使用 Milestones 版或者 Snapshots 版本,需要在 pom 文件里添加以下依赖,否则在下载不下来。
<!--Milestones-->
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones Repository</name>
<url>https://repo.spring.io/milestone</url>
</repository>
</repositories>
2
3
4
5
6
7
8
<!--Snapshots-->
<repositories>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshot Repository</name>
<url>https://repo.spring.io/snapshot</url>
</repository>
</repositories>
2
3
4
5
6
7
8
# Reactor 入门
Reactor 是 Reactive Programming(反应式编程)范式的一种实现。
微软在 .NET 生态系统中创建了反应式扩展(Rx)库迈出了向反应式编程方向的第一步。随后,RxJava 在 JVM 上实现了反应式编程。随着时间的推移,Java 通过 Reactive Streams 努力实现了标准化,该规范为 JVM 上的反应式库定义了一系列接口和交互规则。其接口已集成到 Java 9 的 Flow 类中。
在面向对象的语言中,反应式编程范式通常是观察者模式的扩展。也可以与迭代器设计模式进行比较,因为所有这些库中的 Iterable - Iterator 对都具有二重性。其中一个主要区别是,迭代器是基于拉的,而反应流则是基于推的。
迭代器模式是一种命令式编程(Imperative Programming)模式,尽管访问值的方法完全由 Iterable 负责。但是实际上,开发者需要决定何时访问序列中的下一个元素(即调用 next() 方法)。在反应式流中,与上述 Iterable-Iterator 对等的模式是发布者 - 订阅者(Publisher-Subscriber)模式。但在这种模式中,是发布者通知订阅者新值的可用性,这种推送(push)特性是反应式的关键。
除了推送值,错误处理和完成方面也有明确的定义。一个 Publisher 可以向其 Subscriber 推送新值(通过调用 onNext ),但也可以发出错误信号(通过调用 onError )或完成信号(通过调用 onComplete )。错误和完成都会终止序列。这可以归纳如下
onNext x 0..N [onError | onComplete]
这种方法非常灵活。该模式支持无值、一个值或 n 个值(包括值的无限序列,如时钟的持续滴答声)的用例。
# 为什么需要 Reactive?
# 1. 阻塞会造成浪费
想象一下传统的餐厅服务模式:
- 客人(请求):一位客人坐下,点了一道需要长时间烹饪的菜(比如慢炖牛肉)。
- 厨师(线程):餐厅为这位客人分配了一位专属厨师。
- 阻塞等待:这位厨师从接单开始,就一直站在炉灶前,全程等待这道菜烹饪完成。在此期间,他不能去服务其他客人。
- 完成服务:菜做好后,厨师端给客人,然后才能被解放出来,去服务下一位客人。
这个模型的问题是什么?
- 资源浪费:厨师(线程)大部分时间都在 “等待”(I/O 等待,如等待数据库、网络响应),而不是在工作。这是一种巨大的资源浪费。
- 扩展性极差:如果餐厅同时来了 100 位客人,你就需要雇佣 100 位厨师。厨师的工资(线程的内存开销)非常昂贵!餐厅的厨房(服务器内存)很快就会爆满。
- 脆弱性:一旦厨房里坐满了厨师,新来的客人就只能在外面排队(请求延迟),甚至被直接拒绝(服务不可用)。整个餐厅系统会变得非常缓慢甚至瘫痪。
这就是传统 “线程 - per - 请求” 的阻塞模型。它在并发量小的时候工作良好,但一旦面临高并发,就会立刻撞上性能天花板。
# 2. 异步也无法解决
异步模型并非万能银弹,它有几个根本性的局限。
- 无法解决 CPU 密集型任务
这是最核心的局限。异步模型的优势在于等待。当一个任务在等待 I/O(网络、磁盘)时,CPU 可以被释放去处理其他任务。
但是,如果一个任务本身就需要大量的 CPU 计算,比如:
- 复杂的科学计算
- 视频编码与解码
- 大规模数据的加密 / 解密
这些任务没有 “等待” 时间,它们会持续占用 CPU。
- 在传统模型中:你会启动多个线程,让它们在不同的 CPU 核心上并行计算,充分利用多核优势。
- 在异步模型中:你通常只有一个(或少数几个)事件循环线程。如果这个线程被一个耗时的计算任务卡住,它就无法处理任何其他 I/O 事件。整个事件循环会被阻塞,导致所有请求都得不到响应,系统看起来就像 “卡死” 了一样。
一个形象的比喻:
- I/O 密集型:服务员去厨房下单,他可以在厨房门口等待,也可以先去服务别的客人。等待是可被利用的间隙。
- CPU 密集型:服务员接到一个任务,需要他亲手花 10 分钟揉一个复杂的面团。在这 10 分钟里,他什么也干不了,只能死死地揉面。即使有再多客人,他也无法响应。
结论:对于 CPU 密集型任务,传统的多线程并行模型通常是更好的选择。
- 无法消除物理延迟
异步不能让网络变快,也不能让硬盘读取加速。一个数据库查询需要 100ms,无论你用同步等待还是异步回调,这 100ms 的物理延迟是客观存在的。
- 异步提高的是吞吐量:在等待这 100ms 的时候,系统可以处理成千上万个其他请求。
- 异步不降低单次请求的延迟:对于那个发起查询的用户来说,他依然需要等待至少 100ms 才能拿到结果。
- 手动处理多个异步依赖是极其困难的,会陷入回调地狱之中。
很多人误以为 “异步 = 快”,这是一个需要澄清的误区。异步是高效,不一定是高速。
举个例子:在用户界面上显示用户的前五个收藏,如果用户没有收藏,则显示建议。这需要通过以下三种服务(一种是提供收藏 ID,第二种是获取收藏详细信息,第三种是提供包含详细信息的建议)。那么代码就会变成如下这样。
// 需求很好理解,但是如果只从代码上去看,基本上很难直接看懂。
userService.getFavorites(userId, new Callback<List<String>>() {
// 成功时调用
public void onSuccess(List<String> list) {
if (list.isEmpty()) {
suggestionService.getSuggestions(new Callback<List<Favorite>>() {
public void onSuccess(List<Favorite> list) {
UiUtils.submitOnUiThread(() -> {
list.stream()
.limit(5)
.forEach(uiList::show);
});
}
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
});
} else {
list.stream()
.limit(5)
.forEach(favId -> favoriteService.getDetails(favId,
new Callback<Favorite>() {
public void onSuccess(Favorite details) {
UiUtils.submitOnUiThread(() -> uiList.show(details));
}
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
}
));
}
}
// 出错时调用
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# Reactive 的真正价值是什么?
回到上面的问题中,Reactive 提供了很好的解决方案。
# 1. Reactive 非阻塞模型
- 客人(请求):一位客人坐下,点了一道慢炖牛肉。
- 服务员(事件循环线程):餐厅只有一位非常高效的服务员。他记下客人的菜单,然后把订单交给厨房。
- 非阻塞,立即释放:服务员不会在厨房门口傻等。他立刻回到大厅,去服务下一位客人,或者给其他桌倒水。他从不阻塞。
- 回调 / 事件驱动:当厨房把菜做好后,它会按一下铃(发出一个 “完成” 事件)。服务员听到铃声后,才去把菜端给对应的客人。
这个模型的优势是什么?
- 极高的资源利用率:服务员(少量线程)几乎从不空闲,总是在处理事情。他一个人就能高效地服务几十甚至上百桌客人。
- 极好的扩展性:无论来多少客人,餐厅都只需要这一位服务员。系统的资源消耗是固定的、可预测的,不会随着并发量线性增长。
- 高弹性和响应性:即使客人再多,服务员也只是更忙一点,但系统不会崩溃。新来的客人总能被快速响应(至少服务员能过来记个单),而不会在门口无限等待。
这就是 Reactive 非阻塞模型。它用少量、固定的线程,通过事件驱动和回调机制,处理海量的并发操作。
# 2. Reactive 管理异步的复杂性
下面的代码对上面的代码进行简化
// 使用reactor之后整个代码就变成这样了
userService.getFavorites(userId)
.flatMap(favoriteService::getDetails) // 将Favorite转成流
.switchIfEmpty(suggestionService.getSuggestions()) // 如果Favorite为空,那么从suggestionService拿推荐
.take(5) // 只获取5个
.publishOn(UiUtils.uiThreadScheduler())
.subscribe(uiList::show, UiUtils::errorPopup);
2
3
4
5
6
7
再拓展一下,如果在 800ms 以内没有检索到收藏 ID,则从缓存中获取它们。在基于回调的代码中,这是比较复杂的处理逻辑。在 Reactor 中,只需在链中添加一个 timeout 操作符即可,如下所示:
userService.getFavorites(userId)
.timeout(Duration.ofMillis(800)) // 超过800ms
.onErrorResume(cacheService.cachedFavoritesFor(userId)) // 从缓存中获取
.flatMap(favoriteService::getDetails)
.switchIfEmpty(suggestionService.getSuggestions())
.take(5)
.publishOn(UiUtils.uiThreadScheduler())
.subscribe(uiList::show, UiUtils::errorPopup);
2
3
4
5
6
7
8
# 3. Reactive 管理系统的弹性:背压
这是 Reactive 最独特的贡献之一。单纯的异步模型没有背压概念。
想象一个场景:一个快速的生产者(如股票行情源)和一个慢消费者(如写入数据库)。
- 没有背压的异步:生产者会快速产生事件,消费者异步处理。但消费者的处理队列会无限增长,最终导致内存溢出。
- 有背压的 Reactive:消费者可以主动向上游反馈:“我只能处理 10 个”,生产者就会暂停发送。这是一种主动的、系统级的自我保护机制,是单纯的异步所不具备的。
# 4. Reactive 管理不确定性:统一的错误处理
在异步世界里,错误可能在任何时间点发生。Reactor 提供了 onErrorReturn , onErrorResume , retry 等操作符,让你可以在数据流的任何位置定义统一的错误恢复策略,而不是在每个回调里写 try-catch 。
# 拓展:异步编程存在的问题?
Future 和 CompletableFuture 。它们解决了 “如何获取一个异步任务的结果” 这个问题,但它们并没有完全解决 “如何优雅地处理异步数据流” 这个问题。
Future 对象比回调要好一些,但在组合方面仍然做得不好,尽管 CompletableFuture 在 Java 8 中有所改进。将多个 Future 对象协调在一起是可行的,但是也并不直观。此外, Future 还有其他问题。
调用
get()方法很容易导致Future对象出现另一种阻塞情况。不支持懒计算,
CompletableFuture关联的任务通常是急切执行的,而响应式流(如Flux)是真正懒的,只有在被订阅时才会启动数据生产。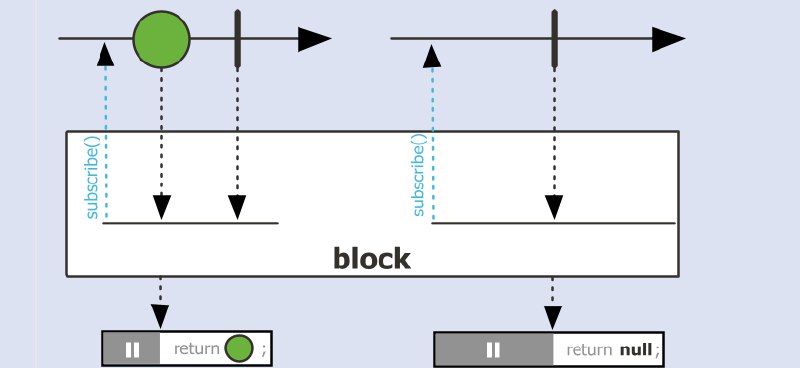
不支持多值和高级错误处理。
再看一个例子:我们得到一个 ID 列表,想从中获取一个名称和一个统计信息,然后将它们配对组合,所有这些都是异步完成的。下面的示例使用 CompletableFuture 类型的列表实现了这一功能:
CompletableFuture<List<String>> ids = ifhIds();
CompletableFuture<List<String>> result = ids.thenComposeAsync(l -> {
Stream<CompletableFuture<String>> zip =
l.stream().map(i -> {
CompletableFuture<String> nameTask = ifhName(i);
CompletableFuture<Integer> statTask = ifhStat(i);
// 合并两个结果
return nameTask.thenCombineAsync(statTask, (name, stat) -> "Name " + name + " has stats " + stat);
});
List<CompletableFuture<String>> combinationList = zip.collect(Collectors.toList());
CompletableFuture<String>[] combinationArray = combinationList.toArray(new CompletableFuture[combinationList.size()]);
// 一起执行
CompletableFuture<Void> allDone = CompletableFuture.allOf(combinationArray);
return allDone.thenApply(v -> combinationList.stream()
.map(CompletableFuture::join)
.collect(Collectors.toList()));
});
List<String> results = result.join();
assertThat(results).contains(
"Name NameJoe has stats 103",
"Name NameBart has stats 104",
"Name NameHenry has stats 105",
"Name NameNicole has stats 106",
"Name NameABSLAJNFOAJNFOANFANSF has stats 121");
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
// 用reactor改造
Flux<String> ids = ifhrIds();
Flux<String> combinations =
ids.flatMap(id -> {
Mono<String> nameTask = ifhrName(id);
Mono<Integer> statTask = ifhrStat(id);
return nameTask.zipWith(statTask,
(name, stat) -> "Name " + name + " has stats " + stat);
});
Mono<List<String>> result = combinations.collectList();
// 阻塞,等待所有任务完成,和CompletableFuture.allOf差不多。
List<String> results = result.block();
assertThat(results).containsExactly(
"Name NameJoe has stats 103",
"Name NameBart has stats 104",
"Name NameHenry has stats 105",
"Name NameNicole has stats 106",
"Name NameABSLAJNFOAJNFOANFANSF has stats 121"
);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
好的,这份 Flux 文档的结构和内容已经非常出色了!特别是对 doOnXXX 、 onXXX 和 hookOnXXX 的区分和总结表格,做得非常清晰。
我将在此基础上,帮你修正一些细节、补充几个关键的高级概念,并优化示例代码,使其成为一份更加全面和权威的 Flux 指南。
# Flux
提示
Flux 是一个可以发射多个数据项的异步消防水管。一旦打开阀门(订阅),水(数据)就会源源不断地流出来,直到水管排空(序列结束)或者发生爆管(错误)。
# Flux 的核心概念
- 发射 0 到 N 个元素:这是
Flux与Mono最根本的区别。它可以代表一个数据流,例如:- 来自数据库的多条查询结果。
- 来自消息队列(如 Kafka, RabbitMQ)的连续消息。
- 用户界面的一系列点击事件。
- 一个定时器周期性发出的时间戳。
- 异步与背压:
Flux是 Reactive Streams 规范的实现。这意味着它天生是异步的,并且强制支持背压。下游的订阅者可以向上游的发布者反馈自己的处理能力,从而避免因生产者速度过快而导致系统崩溃。 - 声明式 API:与
Mono一样,你通过一系列操作符来声明一个数据处理流水线。这个流水线本身是惰性的,只有在被订阅时才会真正开始工作。
# 如何创建 Flux
创建 Flux 是使用它的第一步。Reactor 提供了非常丰富的静态工厂方法。
# 1. 从已知数据创建
// 1. Flux.just() - 从一个或多个直接指定的元素创建
Flux<String> fluxFromJust = Flux.just("Apple", "Banana", "Cherry");
// 2. Flux.fromIterable() - 从任何 Iterable 集合创建
List<Integer> list = Arrays.asList(1, 2, 3, 4);
Flux<Integer> fluxFromList = Flux.fromIterable(list);
// 3. Flux.fromArray() - 从数组创建
String[] array = {"A", "B", "C"};
Flux<String> fluxFromArray = Flux.fromArray(array);
2
3
4
5
6
7
8
9
10
# 2. 创建序列
// 4. Flux.range() - 创建一个整数序列
// 从 1 开始,发射 5 个元素:1, 2, 3, 4, 5
Flux<Integer> rangeFlux = Flux.range(1, 5);
// 5. Flux.interval() - 创建一个从 0 开始的递增 Long 序列,并按指定周期发射
// 每隔 1 秒发射一个数字:0, 1, 2, 3...
// 默认运行在 Schedulers.parallel() 线程池上
Flux<Long> intervalFlux = Flux.interval(Duration.ofSeconds(1));
2
3
4
5
6
7
8
# 3. 程序化生成
// 6. Flux.generate() - 同步地、逐个地生成元素
// 适用于状态同步生成
Flux<String> generatedFlux = Flux.generate(
() -> 0, // 初始状态
(state, sink) -> {
sink.next("3 x " + state + " = " + (3 * state)); // 发射一个元素
if (state == 10) sink.complete(); // 当状态达到10时,完成流
return state + 1; // 返回下一个状态
}
);
// 7. Flux.create() - 更灵活的异步创建方式
// 适用于桥接现有的异步API,如监听器
Flux<String> listenerFlux = Flux.create(sink -> {
// 模拟一个事件监听器
someAsyncEventListener(event -> {
sink.next(event.getData()); // 当事件到达时,发射数据
if (event.isLast()) {
sink.complete();
}
});
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 4. 使用 Sinks 创建 (推荐)
Sinks 是 Reactor 3.4+ 引入的、更安全、更灵活的以编程方式创建 Flux 和 Mono 的方式,是 Flux.create 和 Mono.create 的现代化替代品。
// Sinks.many().multicast(): //多播 创建一个可以向多个订阅者广播数据的 Sink
// Sinks.many().unicast(); // 单播,这个管道只能绑定单个消费者
// Sinks.many().replay(); // 重放,这个管道可以重放元素,把之前的元素重发
// 它支持背压,并且是线程安全的
Sinks.Many<String> sink = Sinks.many().multicast().onBackpressureBuffer();
Flux<String> fluxFromSink = sink.asFlux();
// 在其他线程中,可以向 sink 推送数据
sink.tryEmitNext("Hello");
sink.tryEmitNext("World");
sink.tryEmitComplete();
// 订阅者可以接收到这些数据
fluxFromSink.subscribe(System.out::println); // 输出: Hello, World
2
3
4
5
6
7
8
9
10
11
12
13
14
15
提示
目前项目中真实在用的方式。这个架构的核心是解耦和实时通信:
解耦请求与处理:用户的 HTTP 请求(
customAi)是瞬时的,而 AI 算法处理是耗时的。不能让 HTTP 连一直等待结果。因此,系统采用 “请求 - 响应 - 分离” 模式:- 请求:HTTP 接口立即返回一个
Flux,作为数据传输的 “管道”。 - 处理:真正的 AI 任务被异步地投递到消息队列(RabbitMQ)中,由后台消费者处理。
- 请求:HTTP 接口立即返回一个
通过 Sinks.many ().multicast () 多播的方式来使得同一时间可供给多个消费者,questionId 为唯一键来隔离会话。
/** 接收mq发送的消息 **/
@RabbitListener(queues = "${screening.mq.screen-queue-name}")
public void receiveMsg(String message) {
log.info("【收到AI定制处理计划】:{}", message);
try {
CustomAiAlgoResDTO algoReportDTO = JSONUtil.toBean(message, CustomAiAlgoResDTO.class);
if (Objects.isNull(algoReportDTO)){
log.warn("【收到报告解读消息】数据解析失败:{}", message);
}
// 响应到对应的数据流
streamService.pushScreenCustomSink(algoReportDTO.getId(), JSONUtil.toJsonStr(algoReportDTO));
// 关闭数据流
if (1 == algoReportDTO.getCompleted()){
streamService.delScreenCustomSink(algoReportDTO.getId());
}
} catch (Exception e) {
log.warn("【收到报告解读消息】处理异常:{}", e.getMessage());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
public class StreamService {
/** 报告解读数据流 */
private final ConcurrentHashMap<String, Sinks.Many<String>> reportAnalyzeSinks = new ConcurrentHashMap<>();
/**
* 获取筛查定制数据流
* @param questionId 问题ID
*/
public Flux<String> getScreenCustomSink(String questionId) {
Sinks.Many<String> questionSink = reportAnalyzeSinks.get(questionId);
return Objects.nonNull(questionSink) ?
questionSink.asFlux() :
Flux.using(() -> createReportAnalyzeSink(questionId),
Sinks.Many::asFlux,
sink -> delScreenCustomSink(questionId));
}
/**
* 给筛查定制数据流推送数据
* @param questionId 问题ID
* @param data 数据
*/
@Override
public Boolean pushScreenCustomSink(String questionId, String data) {
Sinks.Many<String> reportAnalyzeMany = reportAnalyzeSinks.get(questionId);
reportAnalyzeMany.tryEmitNext(data);
return true;
}
/**
* 创建报告解读数据流
* @param questionId 问题ID
*/
private Sinks.Many<String> createReportAnalyzeSink(String questionId) {
return reportAnalyzeSinks.computeIfAbsent(questionId, k -> Sinks.many().multicast().onBackpressureBuffer());
}
/**
* 移除筛查定制数据流
* @param questionId 问题ID
*/
public void delScreenCustomSink(String questionId) {
Sinks.Many<String> sink = reportAnalyzeSinks.get(questionId);
if (null != sink) {
sink.tryEmitComplete();
reportAnalyzeSinks.remove(questionId);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
@Override
public Flux<String> customAi(CustomAiParams params) {
String questionId = params.getQuestionId();
// 创建流对象并响应
Flux<String> reportAnalyzeSink = streamService.getScreenCustomSink(questionId);
// 调用算法
CustomAiAlgoDTO customAiAlgoDTO = new CustomAiAlgoDTO();
customAiAlgoDTO.setId(questionId);
// ....省略封装
ThreadUtil.execAsync(() -> {
HttpClient.sendPost(customAiUrl, JSONUtil.parseObj(customAiAlgoDTO));
}
);
return reportAnalyzeSink;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
@Operation(summary = "AI定制处理")
@PostMapping(value = "/customAi", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> customAi(@RequestBody @Valid CustomAiParams params) {
return screenPatientService.customAi(params);
}
2
3
4
5
# 操作符 - 构建数据处理流水线
# 1. 转换类操作符
Flux.range(1, 5)
.map(i -> i * 2) // map: 一对一转换,1->2, 2->4, ...
.filter(i -> i > 5) // filter: 过滤,只保留大于5的元素
.subscribe(System.out::println); // 输出: 6, 8, 10
2
3
4
flatMap 用于将每个元素映射为一个新的 Flux,然后将所有这些 Flux 扁平化合并成一个 Flux 。
// 假设有两个服务调用
Flux<Integer> ids = Flux.just(1, 2, 3);
// 对于每个 id,异步地获取一个用户详情
// fetchUserDetails(id) 返回的是一个 Mono<UserDetail>
// flatMap 会订阅这个 Mono,并在其发出结果后将结果发射到主 Flux 中
Flux<UserDetail> userDetails = ids.flatMap(id -> {
return fetchUserDetails(id);
});
// 如果 fetchUserDetails 返回 Flux,flatMap 也能完美处理
// Flux<Item> items = ids.flatMap(id -> fetchItemsForUser(id));
2
3
4
5
6
7
8
9
10
11
12
# 2. 组合类操作符
Flux<String> flux1 = Flux.just("A", "B", "C");
Flux<String> flux2 = Flux.just("D", "E", "F");
// merge: 交错合并两个流,不保证顺序
Flux<String> merged = Flux.merge(flux1, flux2); // 可能输出 A, D, B, E, C, F
// concat: 按顺序连接,等前一个流完成后再订阅下一个
Flux<String> concatenated = Flux.concat(flux1, flux2); // 输出 A, B, C, D, E, F
// zip: 一对一配对,等待所有源都发射了元素后才将它们组合
Flux<String> zipped = Flux.zip(flux1, flux2, (s1, s2) -> s1 + s2);
// 输出: AD, BE, CF
2
3
4
5
6
7
8
9
10
11
12
# 订阅 - 启动流水线
Flux 是惰性的,定义好流水线后,必须通过 subscribe() 来启动它。
# 1. 基础订阅
Flux.just("red", "green", "blue")
.subscribe(); // 启动了,但什么也不做
Flux.just("red", "green", "blue")
.subscribe(color -> System.out.println("Color: " + color)); // 处理每个元素
Flux.just("red", "green", "blue")
.subscribe(
color -> System.out.println("Color: " + color), // onNext
error -> System.err.println("Error: " + error), // onError
() -> System.out.println("Stream completed!") // onComplete
);
2
3
4
5
6
7
8
9
10
11
12
# 2. 终端操作符
这些操作符会隐式地触发订阅,并将结果收集起来。
// collectList: 将所有元素收集到一个 List 中,返回 Mono<List<T>>
Mono<List<String>> listMono = Flux.just("a", "b", "c").collectList();
listMono.subscribe(list -> System.out.println(list)); // 输出 [a, b, c]
// count: 计算元素数量,返回 Mono<Long>
Mono<Long> countMono = Flux.range(1, 10).count();
countMono.subscribe(cnt -> System.out.println("Count: " + cnt)); // 输出 Count: 10
// block(): 阻塞当前线程,等待流结束并返回最终结果
// **警告**: block() 应谨慎使用,主要在测试或无法使用异步环境时使用,可能导致死锁。
List<String> blockedList = Flux.just("x", "y", "z").collectList().block();
System.out.println(blockedList); // 输出 [x, y, z]
2
3
4
5
6
7
8
9
10
11
12
# 错误处理与恢复
在响应式流中,错误是一个终止事件。一旦发生错误,整个流就会停止。Reactor 提供了多种操作符来优雅地处理错误。
Flux.just(1, 2, 0, 4)
.map(i -> 10 / i) // 当 i=0 时会抛出 ArithmeticException
//.onErrorReturn(-1) // 发生错误时,返回一个默认值 -1 并正常结束流
.onErrorResume(e -> Flux.just(99, 100)) // 发生错误时,切换到一个备用流
.subscribe(
result -> System.out.println("Result: " + result),
err -> System.err.println("Unhandled Error: " + err), // 如果上面的错误处理没起作用,会到这里
() -> System.out.println("Finished!")
);
2
3
4
5
6
7
8
9
# 调度器 - 控制线程执行
默认情况下,操作符会继续在发布者所在的线程上执行。你可以使用 publishOn 和 subscribeOn 来切换执行线程。
publishOn: 影响其后续操作符的执行线程。subscribeOn: 影响整个流的订阅和源头数据发射的执行线程。
Flux.just("A", "B", "C")
.map(item -> { // 默认在 main 线程
System.out.println("map 1: " + item + " on " + Thread.currentThread().getName());
return item.toLowerCase();
})
.publishOn(Schedulers.boundedElastic()) // 切换线程池
.map(item -> { // 后续操作在 boundedElastic 线程池中执行
System.out.println("map 2: " + item + " on " + Thread.currentThread().getName());
return item + "_processed";
})
.subscribe();
2
3
4
5
6
7
8
9
10
11
# doOnXXX 系列 - 副作用 “窥视孔”
doOnXXX 系列操作符是副作用操作符。它们像是在数据流上安装的 “窃听器” 或 “监控探头”,可以让你在不改变数据流本身的情况下,观察到流中发生的各种事件,并执行一些外部操作,如日志记录、指标发送、调试打印等。
核心特点:
- 不修改流:它们只是 “看一眼”,然后让数据原封不动地继续向下传递。
- 返回原始流:
doOnXXX的返回值仍然是Flux<T>或Mono<T>本身,所以它们可以无缝地嵌入到操作符链的任何位置。
示例
Flux.range(1, 5)
.doOnSubscribe(subscription ->
System.out.println("Subscribed!")) // 订阅时触发
.doOnNext(i ->
System.out.println("onNext: " + i)) // 每个元素发射时触发
.doOnComplete(() ->
System.out.println("Sequence completed!")) // 流正常完成时触发
.doOnError(error ->
System.err.println("Error occurred: " + error)) // 流发生错误时触发
.doOnTerminate(() ->
System.out.println("Terminated.")) // 流终止时触发(无论成功或失败)
.doOnCancel(() ->
System.out.println("Cancelled!")) // 流被取消时触发
.subscribe();
// 输出:
// Subscribed!
// onNext: 1
// onNext: 2
// ...
// Sequence completed!
// Terminated.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# onXXX 系列 - 错误处理与恢复
这个系列主要用于错误处理,它们是响应式编程中构建弹性系统的核心。与 doOnXXX 只是 “观察” 错误不同, onXXX 操作符会消费错误并改变流的行为。
核心特点:
- 消费错误:一旦
onErrorXXX操作符处理了错误,原始的onError信号就会被 “吞掉”,不会继续向下传递。 - 改变流:它们会根据错误情况,让流以不同的方式继续或结束。
Flux.just(1, 2, 0, 4)
.map(i -> 10 / i)
.doOnError(e -> System.err.println("doOnError saw the error: " + e)) // 只是看一眼,错误会继续传递
.onErrorReturn(-1) // 捕获错误,并返回一个默认值 -1,流正常结束
.subscribe(
result -> System.out.println("Result: " + result),
err -> System.err.println("Final error: " + err), // 这行不会执行,因为错误被 onErrorReturn 消费了
() -> System.out.println("Completed!")
);
// 输出:
// Result: 10
// Result: 5
// doOnError saw the error: java.lang.ArithmeticException: / by zero
// Result: -1
// Completed!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
关键操作符对比:
onErrorReturn(E value):发生错误时,发射一个静态的默认值,然后结束流。onErrorResume(Function<Throwable, Publisher<T>> fallback):发生错误时,切换到一个备用的Flux或Mono。onErrorContinue(BiConsumer<Throwable, Object> errorConsumer):发生错误时,跳过导致错误的那个元素,然后继续处理后续元素。这在处理批量数据时非常有用。onErrorStop():与onErrorContinue相反,它是默认行为,遇到错误就终止整个流。
# hookOnXXX 系列 - 精细化的订阅者控制
这个系列与前两者完全不同。hookOnXXX 不是 Flux 或 Mono 的操作符,而是 BaseSubscriber 这个抽象类中的钩子方法。
当你需要对订阅行为本身进行精细控制,特别是手动管理背压时,你会选择创建一个 BaseSubscriber 的匿名子类,并重写这些钩子方法。
核心特点:
- 不是操作符:它不是链式调用的一部分,而是
subscribe()方法的参数。 - 控制订阅生命周期:让你能介入到订阅、请求、接收、取消等每一个环节。
- 手动背压:最核心的用途是实现自定义的背压策略。
下面的例子展示了如何创建一个每次只请求 1 个元素的订阅者,从而实现精确的背压控制。
// 修正后的示例
Flux<Integer> source = Flux.range(1, 10);
source.subscribe(new BaseSubscriber<Integer>() {
@Override
protected void hookOnSubscribe(Subscription subscription) {
System.out.println("Subscribed!");
System.out.println("Requesting first element...");
request(1); // 必须主动请求,否则不会有数据
}
@Override
protected void hookOnNext(Integer value) {
System.out.println("Received element: " + value);
if (value < 10) {
System.out.println("Requesting next element...");
request(1); // 处理完一个后,再请求下一个
} else {
System.out.println("Last element received, no more requests.");
}
}
@Override
protected void hookOnComplete() {
System.out.println("Stream completed!");
}
@Override
protected void hookOnError(Throwable throwable) {
System.err.println("Error occurred: " + throwable);
}
});
// 输出:
// Subscribed!
// Requesting first element...
// Received element: 1
// Requesting next element...
// Received element: 2
// ...
// Received element: 10
// Last element received, no more requests.
// Stream completed!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# 高级概念与最佳实践
# 1. 热 Flux vs. 冷 Flux
- 冷
Flux:像一张光盘。每个订阅者都会从头到尾播放一遍,订阅者之间互不影响。Flux.just、Flux.range、Flux.fromIterable以及大多数基于generate/create的Flux都是冷的。 - 热
Flux:像一场直播。数据流独立于订阅者存在,订阅者只能从它加入的时刻开始接收数据,错过了就是错过了。Flux.interval是一个典型的热Flux。
转换冷 Flux 为热 Flux
使用 publish() 和 refCount() (或更简单的 share() ) 可以将一个冷 Flux 变成热 Flux ,从而让多个订阅者共享同一个数据流。
Flux<Integer> coldFlux = Flux.range(1, 5).delayElements(Duration.ofMillis(200));
Flux<Integer> hotFlux = coldFlux.publish().refCount(); // 或者 .share()
// 第一个订阅者
hotFlux.subscribe(i -> System.out.println("Subscriber 1: " + i));
try { Thread.sleep(500); } catch (InterruptedException e) {}
// 第二个订阅者,它会错过前几个元素
hotFlux.subscribe(i -> System.out.println("Subscriber 2: " + i));
// 可能的输出:
// Subscriber 1: 1
// Subscriber 1: 2
// Subscriber 1: 3
// Subscriber 2: 3 // 从当前元素开始
// Subscriber 1: 4
// Subscriber 2: 4
// ...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 2. 背压策略
当下游处理速度跟不上上游发射速度时, Flux 提供了多种背压策略来决定如何处理 “积压” 的数据。这些策略通常用在 onBackpressureXXX 操作符中。
Flux.interval(Duration.ofMillis(10)) // 快速生产者
.onBackpressureBuffer(100) // 缓冲最多100个元素,超过则抛出异常
// .onBackpressureDrop() // 丢弃下游无法处理的元素
// .onBackpressureLatest() // 只保留最新的元素,丢弃旧的
.doOnNext(i -> {
try { Thread.sleep(100); } catch (InterruptedException e) {} // 慢消费者
})
.subscribe(System.out::println);
2
3
4
5
6
7
8
# 3. Sinks - 现代化的编程式创建
Sinks 是 Flux.create 和 Mono.create 的现代化替代品,提供了更清晰的 API 和更好的线程安全保证。
Sinks.one(): 创建一个只能发射 0 或 1 个元素的Mono。Sinks.many(): 创建一个可以发射 0 到 N 个元素的Flux。multicast(): 支持多个订阅者,是热流。unicast(): 只支持一个订阅者。replay(): 会向新订阅者重放所有历史数据。
// 创建一个可以向多个订阅者广播的 Sink
Sinks.Many<String> sink = Sinks.many().multicast().onBackpressureBuffer();
Flux<String> flux = sink.asFlux();
flux.subscribe(s -> System.out.println("Subscriber A: " + s));
sink.tryEmitNext("Hello");
flux.subscribe(s -> System.out.println("Subscriber B: " + s));
sink.tryEmitNext("World");
sink.tryEmitComplete();
// 输出:
// Subscriber A: Hello
// Subscriber A: World
// Subscriber B: World
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# onXXX 系列 - 错误处理与恢复
与 doOnXXX 不同, onXXX 系列操作符是错误处理操作符。它们可以捕获上游的错误,并决定如何恢复流,从而阻止错误向下游传播。
# 1. onErrorReturn - 使用静态值恢复
当发生错误时,忽略错误并发射一个静态的默认值。
Mono<String> monoWithError = Mono.error(new IllegalStateException("Failed"));
monoWithError
.onErrorReturn("Fallback Value") // 捕获错误并返回默认值
.subscribe(
value -> System.out.println("Received: " + value),
error -> System.err.println("Should not be here!") // 不会执行
);
// 输出: Received: Fallback Value
2
3
4
5
6
7
8
# 2. onErrorResume - 使用备用 Mono 恢复
这是最灵活的错误恢复方式。当错误发生时,可以动态地切换到一个备用的 Mono 。
Mono<String> primaryService = Mono.error(new RuntimeException("Primary service is down"));
Mono<String> fallbackService = Mono.just("Response from fallback service");
primaryService
.onErrorResume(error -> {
System.out.println("Primary failed, invoking fallback. Reason: " + error.getMessage());
return fallbackService; // 切换到备用 Mono
})
.subscribe(System.out::println);
// 输出:
// Primary failed, invoking fallback. Reason: Primary service is down
// Response from fallback service
2
3
4
5
6
7
8
9
10
11
12
13
# 3. retry - 重试操作
当发生错误时,自动重新订阅上游的 Mono ,尝试最多 n 次。
AtomicInteger attempt = new AtomicInteger(0);
Mono<String> unreliableMono = Mono.fromCallable(() -> {
if (attempt.incrementAndGet() < 3) {
throw new RuntimeException("Temporary failure");
}
return "Success after retries";
})
.retry(2) // 重试2次 (总共会尝试3次)
.subscribe(
System.out::println,
error -> System.err.println("Final failure after all retries: " + error.getMessage())
);
// 输出: Success after retries
2
3
4
5
6
7
8
9
10
11
12
13
14
注意:
retry会在错误发生后立即重试。对于更复杂的场景(如指数退避),应使用retryWhen。
# hookOnXXX 系列 - 全局监控
Hooks 提供了全局性的、跨所有响应式流的监控和修改能力。它们通常用于应用启动时设置,以进行统一的日志记录、追踪或指标收集。
# Hooks.onEachOperator 和 Hooks.onLastOperator
Hooks.onEachOperator: 将一个操作符应用到每一个新创建的操作符上。Hooks.onLastOperator: 将一个操作符应用到每个响应式链的最后一个操作符上。
示例:为所有 Mono 添加全局日志
// 在应用启动时设置
Hooks.onEachOperator(operatorCall -> operatorCall
.call("globalLogger", new MonoLogger()) // 自定义一个日志操作符
);
// ... 应用代码中的任意 Mono
Mono.just("Some data")
.map(String::toUpperCase)
.subscribe(); // 订阅时会触发全局日志
// 自定义日志操作符 (简化版)
class MonoLogger implements CoreSubscriber<Object> {
// ... 实现细节略,主要是包装下游订阅者并在 onNext, onError 等方法中打印日志
// 这是一个高级用法,实际中可以使用 reactor-tools-extra 等库
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 消费 Mono: subscribe() vs block()
Mono 定义了一个异步流程,要触发它,你需要 “消费” 它。主要有两种方式:
# 1. subscribe() - 异步消费
这是标准的、非阻塞的方式。它会启动异步流程,并立即返回,不会等待结果完成。
Mono<String> mono = Mono.just("Async Result");
// 启动异步流程
Disposable disposable = mono.subscribe(
result -> System.out.println("Got result: " + result), // onNext
error -> System.err.println("Error: " + error), // onError
() -> System.out.println("Completed.") // onComplete
);
System.out.println("This line prints immediately.");
// 输出:
// This line prints immediately.
// Got result: Async Result
// Completed.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
subscribe() 返回的 Disposable 对象可以用来取消订阅 ( disposable.dispose() )。
# 2. block() - 阻塞消费
block() 会阻塞当前线程,直到 Mono 发出元素或完成,然后返回结果。如果发生错误,它会抛出异常。
Mono<String> mono = Mono.just("Blocking Result");
String result = mono.block(); // 阻塞等待结果
System.out.println("Got result: " + result);
// 输出:
// Got result: Blocking Result
2
3
4
5
6
7
⚠️ 重要警告:
- 永远不要在响应式环境(如 Spring WebFlux 控制器)中调用
block()。这会阻塞事件循环线程,完全抵消响应式编程的优势,并可能导致应用死锁。block()的合理使用场景包括:在main方法中、单元测试中,或者在与非响应式的遗留代码集成的边界上。
# 高级概念与最佳实践
# 1. 组合多个 Mono
Mono.zip(): 并行执行多个Mono,当它们都成功完成后,将结果组合成一个Tuple。Mono<String> userMono = findUser(1); Mono<String> orderMono = findOrder(123); Mono<Tuple2<String, String>> tupleMono = Mono.zip(userMono, orderMono); tupleMono.subscribe(tuple -> { System.out.println("User: " + tuple.getT1()); System.out.println("Order: " + tuple.getT2()); });1
2
3
4
5
6
7
8
9Mono.when(): 并行执行多个Mono,等待它们全部完成,但忽略它们的结果。返回一个Mono<Void>,适用于编排多个独立的副作用任务。Mono<Void> updateTask = updateUser(user); Mono<Void> logTask = logUpdate(user); Mono.when(updateTask, logTask) .subscribe(() -> System.out.println("All tasks completed."));1
2
3
4
5
# 2. 缓存结果 ( cache() )
cache() 操作符会缓存 Mono 的结果(成功或失败)。后续的订阅者将立即获得缓存的结果,而不会重新执行源操作。这对于昂贵的、只需计算一次的操作非常有用。
Mono<String> expensiveMono = Mono.fromCallable(() -> {
System.out.println("Performing expensive computation...");
Thread.sleep(1000);
return "Computed Value";
}).cache(); // 缓存结果
System.out.println("First subscription:");
expensiveMono.subscribe(System.out::println);
System.out.println("Second subscription:");
expensiveMono.subscribe(System.out::println);
// 输出:
// First subscription:
// Performing expensive computation...
// Computed Value
// Second subscription:
// Computed Value (第二次没有重新计算)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 3. 超时处理 ( timeout() )
timeout() 操作符可以防止 Mono 因下游服务响应慢而无限期等待。如果在指定时间内没有完成,它会发出一个 TimeoutException 。
Mono<String> slowMono = Mono.fromCallable(() -> {
Thread.sleep(2000); // 模拟2秒延迟
return "Finally";
});
slowMono
.timeout(Duration.ofSeconds(1)) // 设置1秒超时
.onErrorResume(TimeoutException.class, e -> Mono.just("Timeout! Using fallback."))
.subscribe(System.out::println);
// 输出: Timeout! Using fallback.
2
3
4
5
6
7
8
9
10
11
# 4. 上下文传递 ( Context )
Context 是一个在响应式链中从上游向下游传递元数据(如请求 ID、用户凭证)的强大机制,它不作为数据流的一部分,而是作为附加信息传递。
String key = "message";
Mono<String> mono = Mono.deferContextual(contextView ->
Mono.just("Hello, " + contextView.get(key))
)
.contextWrite(context -> context.put(key, "Reactor"));
mono.subscribe(System.out::println);
// 输出: Hello, Reactor
2
3
4
5
6
7
8
9
10